ICASSP 2020 through the lens of AIM: a round-up of some of our favourite papers
The 45th International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2020) took place last week, as a fully virtual event for the first time in its history.
Our colleagues at C4DM (Centre for Digital Music), where the AIM CDT is hosted, presented some impressive work, ranging from sound event classification to bird sound detection and more, which you can find in full here. As we’re just entering the research phase of our CDT, we took a back seat and enjoyed the conference as attendees, combing through the presentations to get a grasp of what new research ideas would emerge from the top signal processing conference this year.
Among the nearly 2000 papers presented, we selected a few that are closely related to our research. Below is an overview of what caught our attention.
On Network Science and Mutual Information for Explaining Deep Neural Networks
This paper works toward interpretable neural network models. This work is in part of a bigger move in the machine learning community, to open the so-called “black box” and be able to explain how the machine is learning. This study investigates how the information flows through feedforward networks. They propose using information theory on top of the network science to calculate an information measure that represents the amount of information that flows between two neurons. The technique to codify this information flow is called Neural Information Flow (NIF). Basically, NIF weights the importance that edges of the neurons have in a multilayer perceptron (MLP) or Convolutional Neural Networks (CNN) while using the mutual information between nodes which is modelled as distribution. Feature attribution is computed as follows, an importance value is placed along all the edges of the network, a product of all these values in a given path is calculated, to finally sum all these products across all possible paths from an input and output. NIF provides information on the most crucial paths of a network. Hence, less important parameters can be removed without loss of accuracy, facilitating network pruning at inference time. Furthermore, NIF can help in visualising edge communities, understanding how nodes form communities, for instance in an MLP. This could help in better training of a network, but needs to further be investigated. However, NIF is of a high computation complexity, which seems to be the main area for improvement.
Davis, Brian, et al. “On Network Science and Mutual Information for Explaining Deep Neural Networks.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Link to presentation
Review author: Elona Shatri
Towards High-Performance Object Detection: Task-Specific Design Considering Classification and Localization Separation
This paper tackles the efficiency of object detection. Object detection is a process of simultaneous localisation and classification. While the first one gives the category the object belongs to, the second one tells where this object is located. Both tasks require robust features that well represent an object. However, these tasks have many non-shared characteristics. Classification concentrates on partial areas or the most prominent region during recognition, i.e. the head of a cat, whereas localisation considers a larger area of the image. Classification is translation invariant while localisation has translation variant characteristics. Hence, the authors propose a network that in addition to considering the common properties, also considers task-specific characteristics of both tasks. They propose altering existing object detection in three stages. Having a lower layer that shares less semantic features between classification and localisation. Consequently, separating the backbone layers to learn task-specific semantic features. Finally, fuse these two separated features by concatenating and 1×1 convolution to have the same number of channels with the separated features. Experimental results show that such an approach can encode two-task specific features while improving performance. However, these improvements are not substantial and further detailed investigation is needed for the task-specific objective functions.
Kim, Jung Uk, et al. “Towards High-Performance Object Detection: Task-Specific Design Considering Classification and Localization Separation.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Link to presentation
Review author: Elona Shatri
Unsupervised Domain Adaptation for Semantic Segmentation with Symmetric Adaptation Consistency
Domain adaptation deals with learning a predictor when the training and test sets come from a different distribution. An example of this situation could be semantic segmentation. If a network trained in synthetic images, fully labelled, has to segment real-world images. These two types of distributions are very different; therefore, a mapping of features is needed. Unsupervised domain adaptation uses the labels from the training time to solve tasks in the shifted distribution data with no labels. This paper utilizes adversarial learning and semi-supervised learning for domain adaptation in semantic segmentation. The two stages of this method are image-to-image translation and feature-level domain adaptation. Firstly, images from source domain are translated to the targeted domain using a translation model. Finally, the semantic segmentation model is trained in an adversarial and semi-supervised manner at the same time. This is done by first symmetrically training two segmentation models with adversarial learning and then between the outputs of the two models introduce the consistency into semi-supervised learning to improve accuracy on pseudo labels that highly affect the final adaptation performance. They achieve state-of-the-art performance on semantic segmentation on the GTA-to-Cityscapes.
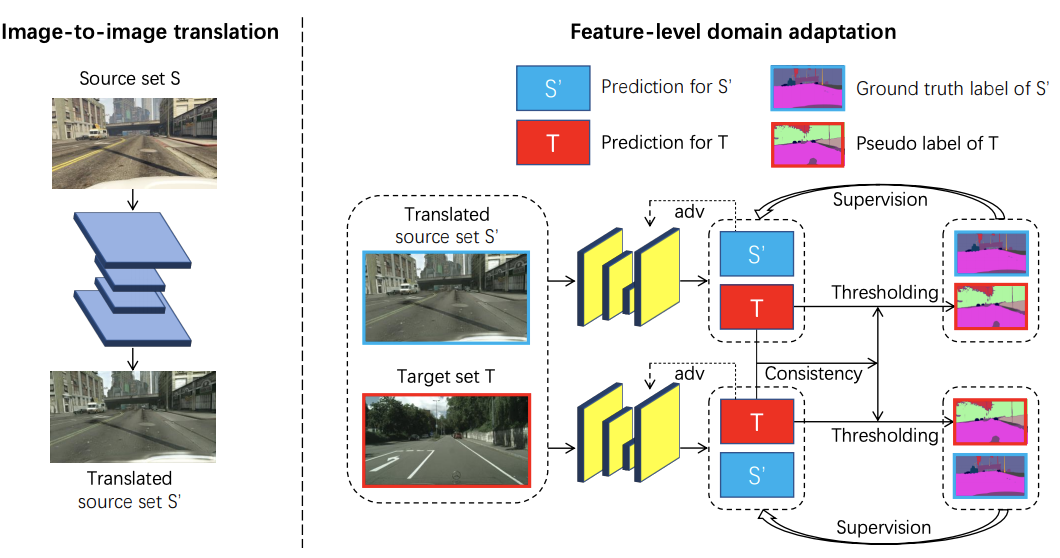
Li, Zongyao, et al. “Unsupervised Domain Adaptation for Semantic Segmentation with Symmetric Adaptation Consistency.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Link to presentation
Review author: Elona Shatri
Large-Scale Weakly-Supervised Content Embeddings for Music Recommendation and Tagging
As large unlabelled datasets are far more common than curated data collections in nearly all domains, it is increasingly important to develop mechanisms that extract supervisory signals from within the data itself. This paper demonstrates a way of doing so in the context of music content where weak supervision is provided by noisy textual metadata and co-listen statistics associated with each audio recording. With the goal of producing an effective music content embedding model, the study focusses on the optimisation of two tasks, co-listen prediction and text label prediction, and demonstrates the usefulness of the proposed model on downstream audio tagging tasks on well-known datasets.
The method proposed is based on a curriculum training procedure, with a triplet loss objective, followed by a classification-like optimisation for text label prediction using a cross-entropy loss. The triplet loss scheme is created through a co-listen graph and with the main goal of constraining the embedding space structure by enforcing notions of music similarity and user preference.
Although the underlying methods adopted are not novel in themselves, their combination sets out an effective strategy for weakly-supervised learning. The use of the co-listen graph to provide contextual information, in particular, is a simple but effective way to disambiguate free-form language. This is naturally dense of useful semantic concepts and hence a powerful supervisory element, but often too ambiguous and noisy to directly replace curated labels.
The goal of obtaining embeddings that capture fine-grained semantic concepts lies at the heart of many learning tasks, and this work offers a perspective on how to leverage the relationships between audio content, free-form text and user context statistics, thus demonstrating that supervision need not come in the form of sanitised labels. This, however, comes with the added cost of a significantly bigger training set, here 10-fold compared to most other studies on audio feature extraction and tagging.
Huang, Qingqing, et al. “Large-Scale Weakly-Supervised Content Embeddings for Music Recommendation and Tagging.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Review author: Ilaria Manco
Disentangled Multidimensional Metric Learning for Music Similarity
Music similarity is a loosely-defined concept and therefore often unsuitable to be directly addressed through traditional metric learning. This paper introduces the concept of multidimensional music similarity obtained by encoding different music characteristics (genre, mood, instrumentation and tempo) as separate dimensions of an embedding space.
The deep metric learning approach presented is an audio-domain adaptation of Conditional Similarity Networks, previously proposed for attribute-based image retrieval. This method presents a variation of triplet networks in which masks are used to activate or block distinct regions of the embedding space during training, resulting in its decomposition into subspaces of features corresponding to one of the dimensions. A regularisation technique is then introduced to enforce consistency across all dimensions, resulting in an increased perceptual similarity as measured in human annotations.
Content-based music similarity is used for the tasks of search and retrieval, particularly in cases where metadata-based methods fall short. It is therefore important to find a way to obtain an optimal embedding that disentangles similarity criteria while minimising distances between perceptually similar music items.
Lee, Jongpil, et al. “Disentangled Multidimensional Metric Learning for Music Similarity.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Review author: Ilaria Manco
Transformer VAE: A Hierarchical Model for Structure-Aware and Interpretable Music Representation Learning.
Two of the most desired features in a music generation system are structure awareness and interpretability. Structure awareness is closely related to music structural coherence and naturalness, and interpretability helps with music understanding and human-computer interaction. This paper proposes a new architecture that combines these two features by adopting the Music Transformer and Deep Music Analogy. The authors call this new model “Transformer VAE”, which can learn both context information and interpretable latent representations from music sequences.
Some changes are made to the vanilla Transformer model to create a VAE setting. Special encoder and decoders are added to the model inputs and outputs to generate latent hidden states for each musical bar.
The self-attention mechanism allows the latent representation generated by the Transformer encoder to contain not only temporal information but also contextual information from other bars. One thing worth mention here is that the authors used a “Masked” multi-head inter attention in the Transformer structure. More specifically, they used an “upper triangular” mask to make the model only attend to the current and previous bars. In this case, the model learns to store the information of the repeated bars only on its first occurrence, which increases the model’s structure interoperability.
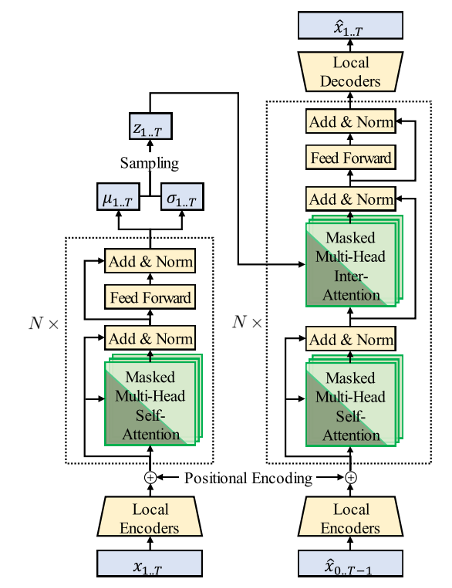
Jiang, Junyan, et al. “Transformer VAE: A Hierarchical Model for Structure-Aware and Interpretable Music Representation Learning.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Review author: Lele Liu
Automatic Lyrics Alignment and Transcription in Polyphonic Music: Does Background Music Help?
Most automatic lyrics alignment and transcription systems perform in two steps: firstly extract the singing voice from the mixed music using a source separation algorithm, and secondly using various methods to extract alignment or transcription information from the “clean” voices. This paper provides a new hypothesis and proved its feasibility – the background music can be kept and can actually help in automatic lyrics alignment and transcription. They proposed genre-informed acoustic modelling and lyrics constrained language modelling method that outperforms existing systems on lyrics alignment and transcription tasks.
Early approaches applied lyrics transcription on solo-singing audio, this paper proposed a new method to train acoustic models using the lyrics annotated polyphonic data directly.
Genre-informed acoustic modelling. Music genres can affect lyrics intelligibility due to the relative volume of the singing vocals compared to the background accompaniment. Also, genres have things to do with the non-vocal segments in music (which is similar to the silence parts in an ASR system). To better capture these differences, this paper proposed to use a “genre-informed” acoustic modelling. Moreover, to avoid dividing music into too many genres, the authors categorize songs into three broad classes based on their shared characteristics – hip-hop, metal, and pop.
Gupta, Chitralekha, Emre Yılmaz, and Haizhou Li. “Automatic Lyrics Alignment and Transcription in Polyphonic Music: Does Background Music Help?.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Review author: Lele Liu
Improving Music Transcription by Pre-Stacking A U-Net
The U-Net, initially developed for medical image segmentation, has been proved useful in different signal processing tasks (e.g. source separation) due to its ability to reproduce tiny details and robustness based on the skip connections. This paper is the first one to use U-Nets in automatic music transcription and experiments showed a positive result.
Pre-stacking U-Net. In this paper, the U-Net architecture is used as a pre-processing step to a automatic music transcription system. The U-Net acts as a transformation network that modifies signal input into a deep neural network-friendly representation, which helped in improving music transcription accuracy.
Multi-instrument transcription. Besides simply improving the overall accuracy of automatic music transcription, the authors explored the potential of the new combined architecture in multi-instrument transcription. By stacking multiple U-Nets before the transcription networks, the new architecture achieved a performance better than the baseline transcription models.
Pedersoli, Fabrizio, George Tzanetakis, and Kwang Moo Yi. “Improving Music Transcription by Pre-Stacking A U-Net.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
Link to paper
Review author: Lele Liu